Privacy and Security in Machine Learning and AI
Artificial Intelligence
Anish Bhardwaj
David Kim
Andrew Huang
1 May 2024
30 min read

Introduction
Hello Weary Traveler! And welcome. In this wiki, you’ll find an introduction to Privacy and Security for AI and Machine Learning. We’ll run you through some tips, tricks, and also link multiple tutorials to useful integrations that you can use in your environment to protect your models, the data you use, and best practices that will help you make sure that you can create a safe and secure pipeline for your Machine Learning Needs. Take a look at our contents section if there’s a specific topic that you are looking for or just browse through if that helps! We hope to help you guys make better decisions with regards to the environments and tools that you use so as to best assist you in making the world of Machine Learning a little more secure.
Acknowledgements
This wiki was part of a quarter-long quest to develop privacy and security educational advice documents that was done at Northwestern University in the first quarter of 2023. The individuals responsible for the creation of this document are Anish Bhardwaj, Andrew Huang, and David Kim. We would like to thank our Professor, Prof. Sruti Bhagavatula for her help and the opportunity to work on this project. While advice in this document has been sourced from various online mediums, we also had the opportunity to interview an expert, Dr.Sharif, and have incorporated his advice across the document as well. We would like to thank him for his contributions as well. We would also like to thank the students and professionals we surveyed for a preliminary question in this project as well as the students of our class who helped iterate over our advice.
Target Audience
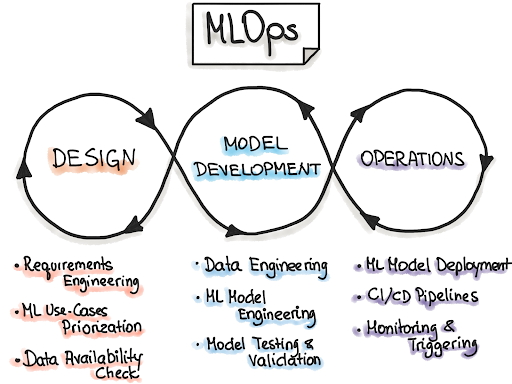
The target audience of our advice document is of course anyone who wishes to learn about Privacy and Security in AI and ML but we have also used terms and referred to tools that are common in the ML space. This is because the focus of our advice is to help individuals in this field and thus a more specialized focus area for us was MLOps engineers. This refers to individuals across the board who work with ML systems, be it for designing new models, maintaining existing models, working with Data and ETL processes, and more. We welcome anyone who wishes to learn more but also acknowledge that the advice is slightly more tailored for this target audience.
The Opinion of ML Engineers
For the purpose of this project, we felt that it was also important to understand how MLOps engineers actually view privacy and security and how important they deem it to the development process. To this effect, we surveyed a mix of 30 professionals and students in this field and these were the results. We asked these individuals to record their opinions on a likert scale from 1 to 5 with 1 being the least important and 5 being the most important.

As can be seen from the results we garnered, most individuals in this space deem Security to have lower importance than Privacy. This is partly due to the fact that individuals seem to believe that Security is the work of Security Engineers with most MLOps engineers focusing on developing robust models or working on Data Transformation processes. The individuals surveyed did show a keen interest in privacy however, partly due to the fact that many of them worked with exclusive or protected data and were aware of the space of data privacy laws and how that could affect the organization.
This survey further illustrates the importance of having such an advice document created. While individuals showed a slightly higher importance for privacy, even this was not a keen enough interest in the field. In the remainder of this document, you will see why it’s important for individuals in this space to be aware of and to take on certain practices for development of AI/ML systems. We will discuss risks and potential problems as well as solutions to such problems in this document. Without further ado, let’s dive into privacy.
Privacy in Machine Learning and AI
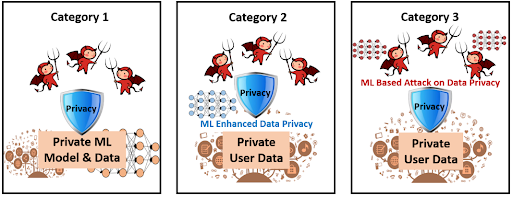
Machine learning takes on a few different roles in the field of privacy, and while this document will focus on building ML systems that are secure towards privacy attacks, it’s important to understand how it can be used in other aspects as well. The first way that ML can be used is as a privacy-enhancing tool; that is, ML models can be trained to read privacy data as input and provide recommendations on mitigation strategies and privacy actions. ML can also be used in an adversarial manner to attack traditional privacy mechanisms and expose sensitive information. Finally, ML models can be targets for privacy attacks aimed at stealing sensitive data in the training set or the model itself.
Before considering how to build a secure ML system, it is important to create a threat model to frame your security decisions around. A threat model is a framework meant to contextualize potential attackers of your system; what resources they have, what parts of your system they have access to, and what their goals are. By using threat models, we can avoid defending against nebulous enemies who’s resources and goals are ill-defined and thus can “shift” around as we make privacy decisions; it makes the discussion less hypothetical and more concrete.
There are two general categories of threat models; white-box and black-box. A white-box model assumes that the attacker has access to the model’s source code and parameters, while a black-box model assumes that the attacker only has access to the outputs of the model. Essentially, a white-box threat has much greater knowledge about how the model works internally and how it produces its results.
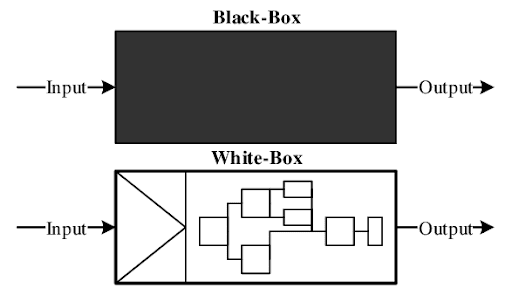
In practice, the black-box model may seem more applicable, as many ML models are not open-source and thus hide their source code and parameters from the public. This is becoming increasingly true with the advent of ML as a service (MLaaS), which focuses on abstracting away the model from the user and focusing only on the outputs. However, it is our recommendation that ML engineers make privacy decisions with the white-box model in mind instead, for two reasons. The first reason is that the white-box threat model represents the worst-case scenario, so defenses against a white-box attack will also be effective against black-box attacks (but not vice versa). Secondly, the black-box model is never a guarantee; a private model can always be stolen or leaked, thus forcibly turning the threat scenario into a white-box one.
Privacy Attacks
In this section, we will summarize some of the most prevalent privacy attacks against ML models, discuss their goals and what part of the system they attack, and some of the methods used to implement them. To contextualize these attacks, imagine a hypothetical ML model that aims to predict cancer diagnoses in patients based on a variety of factors, such as age, gender, race, height, weight, and medical history. Of course, this model contains a lot of sensitive information in the training data and features, making it a good example for our attacks.
Model Extraction
The first kind of attack is a Model Extraction or Model Theft attack. The goal of this attack is quite self-explanatory - to steal or extract the model itself, or if such a thing is not possible, to create a duplicate model. This attack is somewhat unique when compared to the other attacks listed in this document; for one, it only applies in a black-box scenario, as there is no need to steal the model when it is simply available publicly in a white-box scenario. Additionally, this attack does not target the sensitive data, but rather the model itself, and is thus most harmful to the creators and maintainers of the model rather than individuals in the dataset. However, as detailed later, model extraction attacks are defended in the same way as many other privacy attacks, so it is included here.
Model Inversion
Another common form of privacy attack is the Model Inversion attack, which seeks to steal the features of the training set instead of the model itself. In other words, this attack aims to infer various statistical properties of the training set, as well as potentially sensitive features values of individual data records. To use our example with the cancer model, this could mean finding the average age of the training group, the demographic breakdown, or even individual medical histories. This is often accomplished through reversing the gradient of the model and inferring properties of the training inputs based on observed outputs, thus the name of the attack.
Membership Inference
The third kind of attack we’ll discuss in this document is the Membership Inference Attack. This attack aims to determine whether a specific data record is part of the training set of a particular model. This kind of attack is most relevant when participation in the training set itself is a sensitive attribute. This is the case in our example model; being part of a cancer study is itself sensitive information that we want to keep private. Membership inference attacks are most often carried out by “shadow training” techniques, where another ML model is trained to recognize the difference between training and non-training inputs, and is particularly effective against overfitted models.
Privacy Solutions
Now that we have discussed some common forms of privacy attacks against ML, we can look at some of the most effective and simple to implement defenses against them. These fall into two main categories; differential privacy and distribution.
Differential Privacy
Differential privacy is the process of adding random noise to the ML pipeline in order to protect it from privacy attacks. This noise can be added to all parts of the pipeline - pre-processing, in-processing, and post-processing - with various tradeoffs depending on the degree of DP implemented and where it is done.
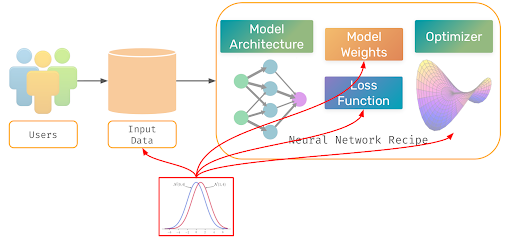
In general, implementing DP in the model (specifically with noise added to the optimizer) has the best balance between privacy protection and performance. Therefore, below we will demonstrate two methods to implement DP in-processing with two popular ML libraries in Python.
Sklearn is a very commonly used python library used for simple implementations of various ML models that abstract away most of the internal details, allowing users to simply pick a model and some simple parameters. IBM has created a companion library called DiffPrivLib that follows the Sklearn format but with differentially-private versions of their models instead. Using DiffPrivLib is as simple as replacing the library import at the top of the page.
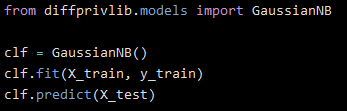
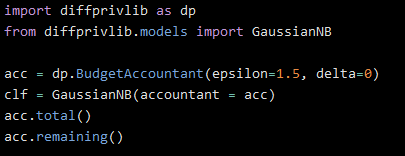
DiffPrivLib also has an extra feature called a budget accountant, that allows you to measure what it calls your “privacy spend”; that is, the amount of computational resources you spend on your differentially private implementation of the model compared to the standard version. You can set a privacy budget and have the accountant alert you when you exceed it, or simply leave the budget undefined and measure your total privacy cost passively.
Another commonly used python library for machine learning is TensorFlow, which also has a DP version called TensorFlow Privacy. This library works by adding a wrapper around the base TensorFlow optimizers in order to implement DP. While the process is slightly more involved than using DiffPrivLib, it is still quite straightforward and does not require many extra lines of code.
The main difference in TensorFlow Privacy is the addition of three new hyperparameters to the optimizer function. The first of these is “l2_norm_clip,” which defines the amount by which you want to clip your gradients in the optimizer. This is to avoid the optimizer reacting strongly to any one particular training data point, reducing overfitting and making the model less vulnerable to membership inference and similar attacks.
The second new hyperparameter is “noise_multiplier,” which is simply a variable determining how much noise you want to add to your gradients. A higher multiplier means more noise and thus a higher privacy guarantee, but lower performance, so this is the hyperparameter you want to pay the most attention to in terms of trade-offs.
The final hyperparameter is “num_microbatches,” which is another performance related variable. This determines the number of microbatches that are used when applying noise to the gradients, with certain batching values being more efficient than others depending on the context of the problem. This value is usually best left as its default value, unless you are trying to seriously optimize the training time of your model.
There are several other ML privacy tools out there, such as OpenDP from Harvard University and Opacus from Facebook. While we will not be covering their usage in this document, you can find links to their GitHub pages below, which include easy-to-follow tutorials and guides for beginners.
Distribution
The other form of privacy protection we will discuss is distribution and aggregation, of both the model and the data. While differential privacy prevents the sensitive data from being extracted or revealed from the model, distribution and aggregation aims to separate the data and model in the first place. There are several different methods of distribution, but they all share the same goal of splitting up the “central” model into smaller components, thus removing the single point of failure present in traditional ML systems.
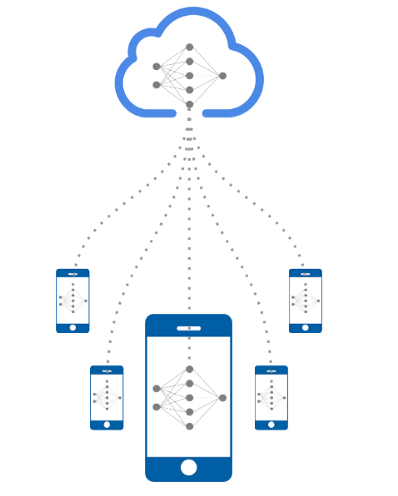
One method of distribution is called distributed learning, in which individual models are trained on the user’s own devices with their individual data, perform classifications, and then vote on the final classification. Another method called federated learning, a term coined by Google, involves the local models submitting their weights and gradients to a central aggregator, which averages them out to create a final model. Either way, the purpose of these distribution methods is the same; to protect individual privacy by keeping data on individual’s devices instead of sending them to a central location, where it can be either intercepted or attacked when it arrives.
Security in Machine Learning and AI
Why is Security important?
Well now that we’ve established problems and solutions on the privacy side of things, let’s talk a little bit about Security. Most people still seem to feel that the Security side of things is the responsibility of solely Security Engineers but, as the scope of the ML Engineer has expanded, there is work on the Security end for MLOps individuals as well. Also, not all organizations have the ability to shell out resources for dedicated Security engineers for every part of the operation which makes it all the more important for MLOps Engineers to take matters into their own hands by incorporating best practices and tools into their pipeline that will improve Security across the board in Machine Learning Production systems. It hasn’t become commonplace yet, but we envision a new bracket opening up amongst MLOps engineers which would be that of the ML Security Engineer.
Now, without digressing too much, let’s discuss the 5 main reasons why MLOps engineers need to talk about security as well.
1: Protecting Sensitive Data
This is something that we have already discussed to an extent in the privacy section but in general, Data can sometimes be sensitive. As AI/ML Production systems become commonplace across the board in areas like Healthcare and the Government, there is a lot of sensitive data out there that’s being used. It’s extremely important to make sure this data is protected.
2: Preventing Malicious Attacks
Contrary to popular belief, AI/ML systems are also the subject of attacks such as DDoS Attacks, Malware Attacks, and some specific attacks that are prevalent amongst only AI/ML production systems. It’s very important to ensure that systems are protected against these attacks so that we can make sure that the systems do not fail or have issues as a result of not incorporating a couple tools that could save the system.
3: Maintaining System Integrity
This is crucial for the security of AI/ML systems because these systems rely heavily on the accuracy and consistency of their data inputs, algorithms, and output results. Any deviation from the expected behavior can compromise the security and reliability of the system, potentially leading to unintended consequences such as incorrect predictions, biased results, or even security breaches. Therefore, maintaining system integrity through careful monitoring, testing, and validation is essential for ensuring the security and trustworthiness of AI/ML systems.
4: Compliance with Regulations
There’s that word again… Regulations. It's important to understand regulations as nowadays, things are changing constantly. In fact, we have an entire section dedicated to this at the end of this document so check it out in case you’re interested in how regulations and Security of models tie into one another.
5: Building Trust with Users
This is important for the security of AI/ML systems because users must have confidence that the system is secure and trustworthy to use it effectively. Trust can be built through transparency, accountability, and effective communication about the system’s capabilities and limitations. This is particularly important for sensitive applications, such as healthcare or finance, where users need assurance that their personal information is being handled securely and ethically. Building trust with users can also help to detect and mitigate potential security risks or malicious attacks, as users are more likely to report suspicious behavior or anomalies when they trust the system.
Now, let’s dive into the nitty gritty of these a little further… starting off with the ML Production pipeline.
AI/ML Pipeline and Risks
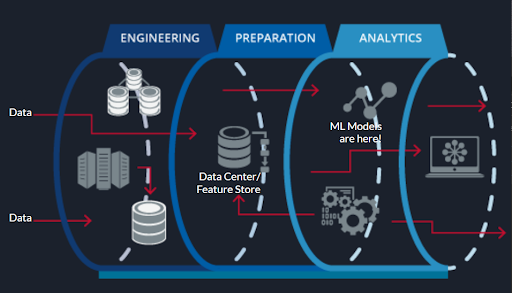
In the diagram showcased here, we can see a very simple example/ high level overview of an AI/ML production pipeline. Of course, this pipeline doesn’t actually showcase all the individual parts as we could create an entire separate document on just the Feature store and risks associated with that! However, the purpose of this diagram is to show that Data Ingestion happens from multiple places and is stored in the feature store after being transformed and put together in the desired manner. From here, Machine Learning models make use of this data to train and the output of these is seen in production at the frontend.
Obviously not all models have a frontend for users to interact with but many do and the focus of this advice document is to highlight the two potential areas where adversaries may attempt to relay attacks. These are the Data and the Machine Learning Models themselves. There is of course a lot more to security and the pipeline itself in an organization which includes backend processes, frontend processes, and so much more but the focus of this document, once again, is on those areas that MLOps engineers need to become privy to, and specifically those areas that deal with the Machine Learning process.
Data Pipeline Risks

Well, here are some types of attacks that a Data Pipeline that is set up for a Machine Learning Production environment might be exposed to. How may each of these happen you may ask… well, read along to find out!
1: DDoS Attacks
- In the case of data pipelines in machine learning production environments , DDoS attacks can be directed at the API endpoints that are used to submit data for processing or receive predictions from the model. Attackers can flood these endpoints with a large number of requests, causing the pipeline to become overloaded and unresponsive. This can result in denial of service for legitimate users or cause delays in processing, which can impact business operations.
2: Malware Attacks
- Malware can be injected into the data pipeline at various stages, such as during data acquisition, preprocessing, or model training. Attackers can use malware to inject biased data into the pipeline or manipulate the machine learning model to produce incorrect results. For example, attackers could inject false data into a pipeline that is used to detect fraudulent transactions, causing the model to incorrectly flag legitimate transactions as fraudulent.
3: Physical Attacks
- Physical attacks can include tampering with the hardware components of the machine learning pipeline, such as the servers or storage devices, or disrupting the power supply or network connections. This can cause data loss or corruption, and compromise the integrity of the machine learning model. For example, attackers could physically tamper with a server that is used to store sensitive data, or disrupt the power supply to cause a system failure.
WHOA… That seems pretty hefty doesn’t it! And that’s exactly the point of this conversation. Many MLOps engineers aren’t even aware that these types of attacks can be levied on their systems. With this being such a new industry and with most of it still being centric to large corporations who have the resources to have Security engineers monitoring these pipelines, it hasn’t been made clear yet as AI/ML systems trickle down to smaller organizations and other corporations that Data Pipelines and ML pipeline are vulnerable to attacks like this as well. But don’t worry, because you’ve made your way to this advice document and will now be equipped with the knowledge of what could happen and how to prevent this in the future.
Best Practices and Tools for Threat Mitigation
Now for these Data Pipelines, let’s talk a little bit about the best practices and tools to help get these practices in order for you to create more Secure pipelines.
1: Access Control
- Access control is a critical security measure for data pipelines in machine learning production environments because it helps to prevent unauthorized access to sensitive data and resources. By implementing access controls, such as role-based access, password policies, and multi-factor authentication, organizations can limit access to data pipelines to only authorized personnel, reducing the risk of data breaches and malicious attacks.
Now that we’ve understood why we need access control, let’s talk about how this can be done. Most ML production systems sit on the cloud and each cloud platform has their own Identity and Access Management (IAM system) in place. We could try and explain each of these here but all cloud providers have their own systems in place and tutorials to have this done, hence we have linked the tutorials for the 3 most famous cloud IAM systems here
2: System Monitoring
- System monitoring is another important best practice for mitigating threats on data pipelines in machine learning production environments. By continuously monitoring system logs and network traffic, organizations can quickly detect and respond to anomalous behavior or security incidents, such as DDoS attacks, malware infections, or data breaches. This can help to minimize the impact of security incidents and prevent them from escalating into more serious problems.
WOW! It’s really that easy is it? Well yes, implementing proper measures such as system monitoring systems can greatly help reduce risk of Malware attacks and DDoS attacks resulting in a very secure system. While there are tons of tools out there, through our research and experiences, we found that the best tools to start off with are Snort and Splunk’s System Monitoring tool. Splunk has an entire interface that can require being integrated with the system which is why the Open-Source tool Snort is a great way to go too.
Here are the links to each of these:
3: Incident Response Planning
- Incident response planning (IRP) is essential for effective security management in machine learning production environments. By developing and testing incident response plans, organizations can ensure that they have the necessary procedures and resources in place to respond quickly and effectively to security incidents. This includes identifying and containing the incident, analyzing the impact, and restoring normal operations as quickly as possible.
It is very important to have an IRP system in place. It’s of course great to have all the safety and security measures setup for the organization but it is equally important to make sure that if an incident does happen, there is a protocol in place. It’s similar to having a fire drill for a building…you don’t want to wait for the fire to happen to discover how to evacuate a skyscraper. Tools like Jira and Trello do have incorporations for IRP systems to be set up but, at the end of the day, IRP systems don’t require tools. We think it’s a great idea for teams to sit together and formulate a plan in case a fire does start. Even so, if your organization does use Jira, here is a tutorial to get your IRP protocol setup.
4: Data Encryption
- Data encryption is a best practice for protecting sensitive data in machine learning production environments. By encrypting data at rest and in transit, organizations can prevent unauthorized access to sensitive information, even if the data is compromised. This can help to protect against data breaches and ensure that sensitive data is kept confidential.
This might be like preaching to the choir but data encryption is important. What’s scary is the fact that many people forget about it. Simple practices while setting up data pipelines can ensure that Data is encrypted all throughout the pipeline. Almost all the cloud systems have their own systems in place similar to how they did for the IAM systems and it’s as easy as clicking a button. However, if you’re not using the cloud, there’s still a solution for you with OpenSSL, an open source library that enables encryption across data pipelines. Here are some tutorials to get you started.
5: Employee Education
- Employee education is a key element of any effective security strategy for machine learning production environments. By educating employees about security best practices, such as strong password management, phishing awareness, and incident reporting, organizations can help to create a culture of security awareness and reduce the risk of human error or negligence. Additionally, regular security training can help to keep employees up to date on the latest threats and best practices, ensuring that they are better equipped to identify and respond to security incidents.
This is an important one… we have to make sure our employees know what is happening. Regular security training, security modules, and workshops can help employees stay up to date. Sometimes the threats may just be a result of a compromised employee and we definitely don’t want that happening. Our personal suggestion is to set up an education portal specific to your organization but if you don’t have that available just yet, there are some online resources (Seriously though? You guys have an organization… tailor the content to your org, PLEASE!)
And that’s it! There’s our recommendations for Security… WAIT A MINUTE… Is this just advice that tailors to best practices, data pipelines, and maybe could be used by anyone who works on cloud based systems? Is this even Machine Learning Tailored?
Well the answer to that is yes and no. This advice is a lot of best practices and anybody who works with cloud based systems could benefit from this advice. A lot of security issues can be resolved just by incorporating these types of practices in our everyday lives. This advice is very good for Data pipelines but at the end of the day, we haven’t really discussed machine learning specific threats yet have we? Well don’t fret…that’s coming up now.
Machine Learning Specific Threats
Ahh yes, the belle of the ball has arrived. Let’s talk about threats that are specific to Machine Learning Models. The advice above is tailored to data pipeline creation and preventing security threats to the Data center. Now however, it’s time to talk about something new…Something more ML based…Something where the consequences could be death…

Take a look at the diagram above. These are the three types of Model attacks we are going to be discussing. For each of them, we will start off by explaining the attack followed by a walkthrough example of such an attack with the consequences, followed finally by the mitigation tactics that can be incorporated with links to tutorials for so many different ways to mitigate these threats. Let’s not dilly dally then… let’s get to it!
Model Poisoning
What an ominous sounding name. Model Poisoning. It’s not just ominous sounding but dangerous as well. Model poisoning is a type of adversarial attack on machine learning models that involves manipulating the training data used to develop the model. In a production ready ML system, model poisoning can occur when an attacker inserts malicious data into the training set, causing the model to learn incorrect or biased information. This can compromise the accuracy and reliability of the model, leading to incorrect predictions or other unintended consequences. This sounds a little complex…So let’s run through an example to understand this better.

I don’t know about you, but that sounds frightening. DAMN THESE ATTACKERS. But don’t worry because you have the unique opportunity to read this advice document and so you are going to find out all the ways to mitigate such a threat to the system.
Model Poisoning Mitigation
1: Input Validation and Sanitization
- Input validation and sanitization can help prevent model poisoning attacks by ensuring that the data used to train the model is clean, consistent, and free from malicious inputs. This involves implementing data validation checks to detect and filter out data that doesn’t meet certain criteria, such as format, data type, or range. Additionally, data sanitization techniques can be used to remove any potentially harmful code or scripts from the data before it is used to train the model.
This would definitely help stop that damn adversary. Here are some handpicked tools/libraries and their tutorials that you can incorporate with your system today to ensure that your system is safe against such threats.
2: Outlier Detection
- Outlier detection is a method for identifying and removing bad data points from the training set, which can help prevent model poisoning attacks. By detecting outliers, organizations can prevent attackers from inserting malicious data into the training set that can skew the model’s learning and compromise its accuracy. Outlier detection can be implemented using statistical methods, machine learning algorithms, or other data analysis techniques.
Outlier detection seems like a fairly simple way to incorporate security doesn’t it? And it is. Just use tools/libraries like the ones listed below to make your system more secure today.
3: Model Monitoring
- Model monitoring is an important component of preventing model poisoning attacks because it allows organizations to detect and respond to any unusual or suspicious behavior in the model. By monitoring the model’s performance and outputs, organizations can quickly detect and respond to any changes in behavior that may indicate a model poisoning attack. This can include monitoring the model’s predictions, performance metrics, and other relevant data points.
Similar to the concept of system monitoring, this helps ensure that our models work properly and without issues. Here are some tools/libraries as well as their tutorials to get you on your way.
4: Data Provenance Tracking
- Data provenance tracking is a technique for tracing the origin and history of data used to train the model, which can help prevent model poisoning attacks. By tracking the source of the data and the steps it went through before being used to train the model, organizations can ensure that the data is trustworthy and free from any malicious inputs. Additionally, data provenance tracking can help organizations identify and address any potential vulnerabilities in their data pipeline.
Once again, similar to the concept of system monitoring, with data provenance tracking we can understand where our data comes from. It’s important to do so to ensure the data is coming from the expected places and here are some tools to help you on your way.
5: Security Audits
- Security audits can help organizations identify and mitigate potential security risks in their machine learning systems… By conducting regular security audits, organizations can identify any vulnerabilities or weaknesses in their systems, and take steps to address them before they can be exploited by attackers. This can include reviewing access controls, network security, data handling practices, and other critical security measures. By reviewing the security of our systems and having third parties do so as well, it can help us find flaws that even we didn’t know existed. Contact a local security team today!
6: Security Training for Employees
- Security training for employees is another important measure for preventing model poisoning attacks. By providing regular training on security best practices, such as password management, phishing awareness, and incident reporting, organizations can ensure that employees are aware of potential security risks and know how to respond to them. Additionally, security training can help to create a culture of security awareness within the organization, making it more difficult for attackers to carry out successful model poisoning attacks. We’ve talked about Security training and given some examples that can be used but we once again urge you to tailor content to the specific systems set up and being built in your organization.
Whoosh… I feel safer already. Take these tactics to heart and implement them into your model pipelines soon! The tutorials shown here also showcase the best ways to do so and prevent an attack like model Poisoning. But wait… there’s more.
Data Poisoning
Wait a second, more poison? That’s right…data poisoning attacks are just as ominous sounding but also slightly different to the way model poisoning attacks work. They still deal with data but in a very different way. Data poisoning is an attack on machine learning models where an attacker introduces malicious data into the training set by means of inputs to the system, which can result in the model making incorrect predictions. In a production ready ML system, data poisoning can occur through various means, such as by introducing biased or false data, by exploiting vulnerabilities in the data pipeline, or by manipulating data inputs in real-time. Sounds a bit confusing and it isn’t that easy to tell how this is different from model poisoning right? But don’t worry…here’s an example to explain this better.

Oh My! This really is a big issue isn’t it…I’m really starting to hate these attackers you know. Recommendation systems are constant targets of such adversaries but don’t fret, we’re here to help you avoid this issue. Remember, you have the unique opportunity to read this advice document and so you are going to find out all the ways to mitigate such a threat to the system.
Data Poisoning Mitigation
1: Input Validation and Sanitization
Input validation and sanitization involves checking and filtering data inputs to ensure that they meet specific criteria and are free from malicious code or scripts. By validating and sanitizing data inputs, organizations can prevent attackers from injecting biased or false data into the recommendation system. This can include techniques such as removing HTML tags, restricting file types, and implementing character filters. We’ve already talked about this above with Model Poisoning attacks but here are the tutorials once again.
2: Model Monitoring
Model monitoring is a critical component of preventing data poisoning attacks in recommendation systems. By monitoring the model’s performance and outputs, organizations can quickly detect and respond to any changes in behavior that may indicate a data poisoning attack. This can include monitoring the model’s predictions, performance metrics, and other relevant data points.We’ve already talked about this above with Model Poisoning attacks but here are the tutorials once again.
3: Anomaly Detection
Anomaly detection is a technique for identifying data points that deviate significantly from the expected behavior or pattern, which can help prevent data poisoning attacks. By detecting anomalies, organizations can identify and remove any malicious or biased data points that may be introduced by attackers. Anomaly detection can be implemented using statistical methods, machine learning algorithms, or other data analysis techniques. Anomaly detection cna help identify a large number of new accounts that are influencing the system as well. We’ve already talked about this above with Model Poisoning attacks but here are the tutorials once again.
4: Data Augmentation
Data augmentation is a technique for increasing the diversity and quantity of training data by generating new synthetic data from existing data. By augmenting the training data, organizations can reduce the impact of any malicious data inputs and increase the resilience of the recommendation system against data poisoning attacks. This can include techniques such as rotating, flipping, or scaling ArticleImages, adding noise to audio files, or perturbing text data.
Now there are so many different types of data that we could be working with but we’ve compiled tools and libraries for data augmentation across the 3 most common ones (ArticleImage, Audio, and Text). We hope these come of use to you!
ArticleImage Data
Audio Data
Text Data
Wow… I just feel like I’m getting safer by the minute… Damn, the authors did a good job huh ;). Now though, we go to perhaps the most interesting attack of them all…the Evasion attack.
Evasion Attacks
Now this is an interesting name for an attack isn’t it…Evasion…What possibly could we be evading? Evasion attacks are a type of adversarial attack on AI/ML systems that involve modifying or manipulating data inputs to evade detection or classification by the system. In a production ready AI/ML system, evasion attacks can occur when attackers introduce subtle changes to the input data, such as adding noise, changing the contrast or brightness, or altering the color. This can cause the model to misclassify the input, leading to incorrect or unexpected results. Now this is where things begin to get murky isn’t it…How is this different from a Data Poisoning attack. Well, maybe this example will help.

Still, can’t see the difference? Well, essentially, a Data Poisoning attack attempts to rework the way a system sorts or works and thus works well on recommendation systems. On the other hand, Evasion attacks solely try to get a system to misclassify an input. These attacks are dangerous and while the example above is a little more fun loving, the consequences of such an attack could be extremely dire. But don’t worry because, and for one final time, you have the unique opportunity to read this advice document and so you are going to find out all the ways to mitigate such a threat to the system.
Adversarial Training as Mitigation
Adversarial training is a technique for strengthening machine learning models against adversarial attacks… specifically evasion attacks as well. It involves inserting adversarial examples into the training data on purpose in order to help the model learn to recognize and respond to these types of attacks more effectively. Adversarial examples are generated by modifying existing data inputs in a way that may be undetectable to humans but causes the model to misclassify the input. This can include adding noise, adjusting the contrast or brightness, random smoothing of the inputs, changing the color of the input, and more.
During the training process, the model is exposed to both regular and adversarial data inputs, allowing it to learn to distinguish between normal and malicious inputs. The model can improve its ability to detect and respond to adversarial attacks by learning from adversarial examples, making it more robust and reliable in real-world scenarios. To create a comprehensive security strategy for machine learning models, adversarial training can be combined with other techniques such as input validation, outlier detection, and regular monitoring. Organizations can help to reduce the risk of adversarial attacks and ensure the reliability and accuracy of their machine learning systems by implementing these best practices.
It is important to note that, while adversarial training can improve the robustness of machine learning models against adversarial attacks, it is not a perfect silver bullet solution. Adversarial attacks are constantly evolving, and new techniques are being developed all the time, so it is critical to remain vigilant and educate yourself while keeping security measures up to date to ensure maximum protection against these types of attacks. Here are some tutorials for adversarial training libraries.
Security Conclusion
Well, we’ve gone over an overview of Security now. Remember, none of these solutions are silver bullets. It is important to create a comprehensive security strategy and combining the best practices with the techniques we mentioned above that are specific to Machine Learning practices is the way to do that.
Laws and Regulations
With AI becoming more prevalent in our lives with AI programs like chatgpt and self-driving cars, user privacy becomes more important than ever as AI processing uses a lot of data to make them better, but what makes AI so dangerous? The first reason is Data Persistence, which is when data continues to persist longer than the process. Even after the program is terminated, the data the program accumulated continues to be stored or used. This is dangerous as profiling exists. Ai systems have the capability to identify who individuals are based on what they put into the systems. Based on a person’s activities, AI systems will be able to figure out their job occupation, age group, likes/dislikes, and their personal information. For example, TikTok uses its AI algorithm to know who the user is. The algorithm will learn where the users live, who their friends are, what they like, what makes them laugh, etc. Even if a user may delete their account or not use the application, that data can still continue to exist. As a result, if there are data breaches, their personal data can be exposed. Also, their data, like many social media companies are already doing, can be sold and shared. This is especially dangerous if this is sold to other malicious parties, as they can use it for scams or identity theft.
The second reason is Data Repurposing, which is data being used beyond their original purpose. As it can be expensive to collect data again, companies reuse old data to feed into their new AI programs. Why is this dangerous? Users would essentially lose control of their data, and they wouldn’t even know it. As a result, they wouldn’t be able to delete data or make any inquiries as they are oblivious. The last reason is Data Spillover, which is data collected on people who are not the target of data collection. This is especially dangerous as users won’t know the data that is collected from them, and it will be difficult for it to be deleted as companies won’t know either.
GDPR and CCPA/CPRA
The two biggest laws that are currently protecting our data privacy are CCPA and GDPR. They make sure that we have the right to know, access, and delete our data and the right to stop companies from selling data unless we give our consent. If the laws are broken, the CCPA will give fines of up to 7500 dollars per violation, and GDPR will give fines up to 4% annual revenue or 20 million euros.
For CCPA/CPRA, companies will have to inform data subjects of the existence of automated decision-making technology, such as profiling, and the right to not be subjected to this processing. The users will be provided with the logic involved with the automated decision making processes, and descriptions of likely outcomes of the process with respect to the consumer also need to be provided.
Similar to CCPA/CPRA, for any important decisions about an individual without human involvement like AI processing, the individual has the right to know about it and object from being included in such processing according to GDPR. The difference between them is a difference in wording. GDPR states that, for AI functions to be subject under GDPR, it must produce legal effects concerning the individual or similarly affect them. For example, targeting advertising like amazon recommending items based on profiling will be difficult to prove that users will be impacted significantly. CCPA/CPRA does not state that, so they can impose rules on any companies that rely on automated decision-making.
The laws are not covering, in terms of the risks covered, data spillover as GDPR and CCPA/CPRA does not protect the unintended targets as both the companies and the targets won’t know. If they don’t know, targets won’t be able to inquire until it’s too late. For data repurposing, both laws cover it as data cannot be reused unless users are notified. Data persistence is also covered by both laws as companies under GDPR can hold onto data for as long as the specified purpose, and for CCPA/CPRA, companies need to state a reasonable length of time.
These risks and laws are important to know as, although laws may not cover all the risks, they will be covered in the future. By preparing for the future, there will be less time and resources spent on past mistakes for failing to do so. It’s also important to protect oneself and others as these AI algorithms will be affecting everyone, not just the consumers. Family members or friends could be an unintended target of the algorithm, and the information that is shared can affect a person for the rest of their life. Also, like previously mentioned, the company will get fined for breaking the law, so there is also a monetary reason.
Important Practices
Our framework will be separated into 5 parts: Practices to make models safe and effective, Designing AI to avoid discrimination, Data Privacy, Notifying Users, and Usage of Model. To make models safe and effective, they must consult with experts and see how the public uses it. Having outside advice and seeing what users see as dangerous is essential in getting a different viewpoint. They must also identify risks and mitigate it, establish oversight mechanisms or processes to watch over AI system so it follows rules and regulations, avoid using inappropriate, low-quality, or irrelevant information, and have data tracked and identified to avoid feedback loops, compounded harms, and inaccurate results, which can help with unintended targets as they will be tracked and removed from the data set.
For designing AI to avoid discrimination, systems should be designed to not discriminate on a characteristic protected by law using a fairness metric, be subjected to disparity assessments and independent evaluation of algorithmic discrimination, have systems reflect a representative and robust data set, but also don’t use data that may fuel algorithmic discrimination, and ensure accessibility for people with disabilities.
For Data Privacy, users need to have agency over their data and not be subjected to surveillance, and they should not be defaulted to choices that are privacy invasive. Also, systems that need to monitor users should not be used outside of housing, education, employment, or any way that limits the user’s civil rights and liberties.
For notifying users, users need to be provided descriptions of overall system functionality, how AI is used, and the different potential outcomes in accessible plain language. It should state how those potential outcomes were determined by the system, including when the AI system is not the sole input, and explanations need to be valid, meaningful, and encompass different types of risks. The user should also be notified on who is responsible for the system and have a way to contact them.
Lastly, for usage of the model, users should be able to opt out of automated systems in favor of alternatives in situations where they may face harmful consequences, be able to receive help in a timely manner and have a fallback process, whether it is automated or human involvement, and AI systems used in sensitive domains like education, employment, etc. should provide users training on how to interact with the system and be able to take in human considerations for adverse or high-risk decisions
Conclusion
Thanks for taking the time to go through our advice document. We know that there is definitely more information out there and each of these topics could have documents of their own but we hope that you enjoyed reading our document and more importantly learned a little more about Security and Privacy in AI and ML. We are confident that you are now capable of creating AI/ML systems with Security and Privacy and mind. Please leave any feedback you have for us in the Comment section below. (If this is a Medium Article/Blog :P)